INSURANCE TECH
Building trust where price usually wins
An AI-guided layer embedded inside an insurance quote flow — designed to close the trust gap hypothesized to be keeping acquisition flat, built entirely under ambiguity with no user research, conversion baselines, or internal data access.
Problem & Constraints
A conversion problem that appeared to be hiding a trust problem
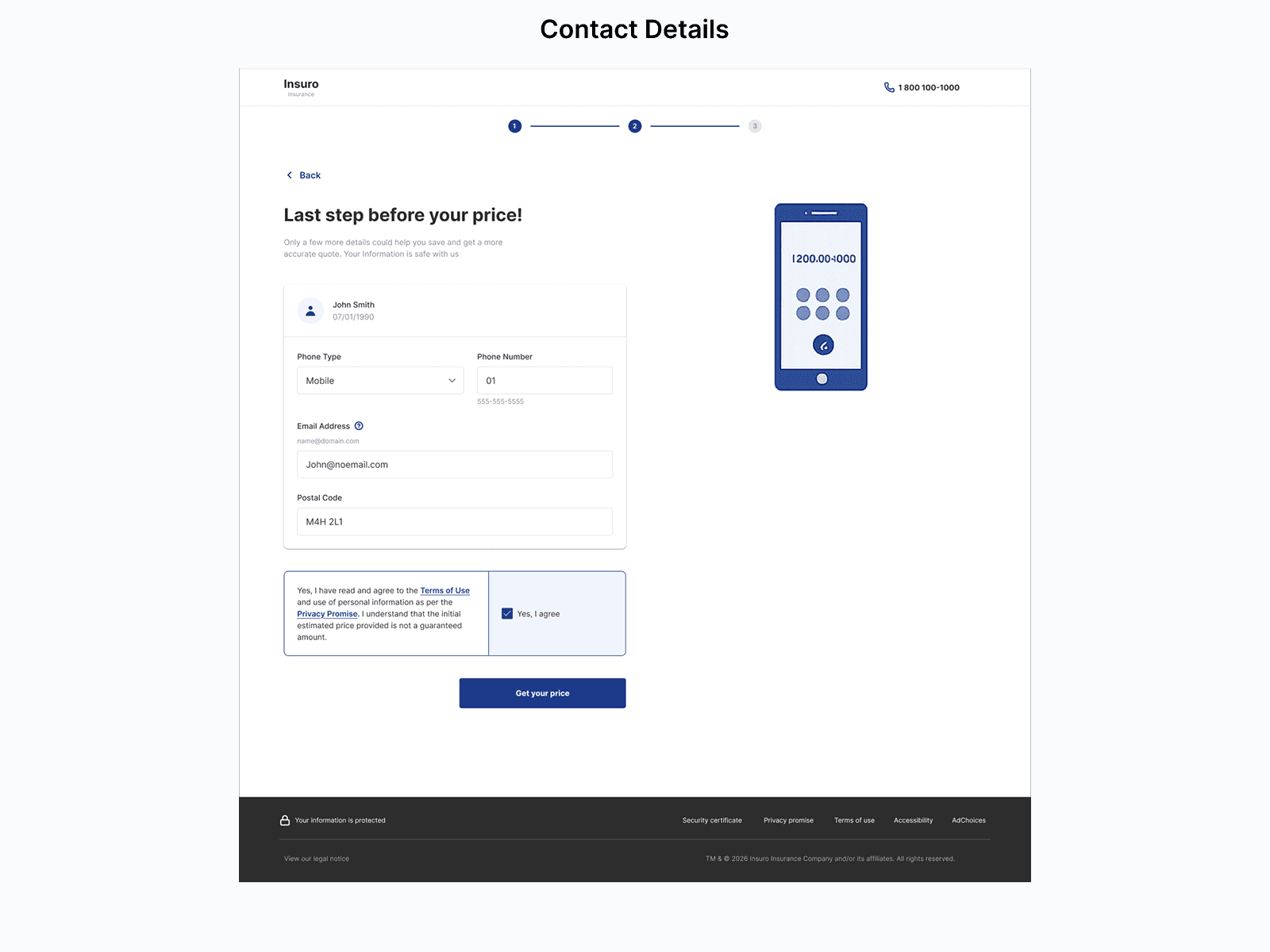
The goal was to increase quote-to-purchase conversion year over year. What made it structurally hard: price is the dominant decision driver in insurance, and it's the one variable a company can't always win on. Users were arriving comparison-ready — increasingly using tools like ChatGPT before ever visiting the site.
The strongest available signal came from sales: clients binding policies were already asking whether rates would rise next year. Not post-purchase anxiety — but a pattern that suggested the product may have been failing to build any mental model of how insurance pricing works before the user made a decision. It wasn't validated data, but it was directionally consistent and specific enough to design against.
" I haven't had any claims. Why are my rates still going up? "
RECURRING PATTERN - SALES TEAM INSIGHT
What was missing
The project started without the inputs most discovery work relies on. Every design decision had to be justified on logic and principle, not evidence.
No User Research
NO Conversion Baseline
No Internal Data Access
No Proof of concept
These constraints defined the approach:
Identify the highest-leverage intervention that didn't require new infrastructure, new data pipelines, or a validated hypothesis to justify building.




Current task flow
Approach
A content problem, not a technology problem
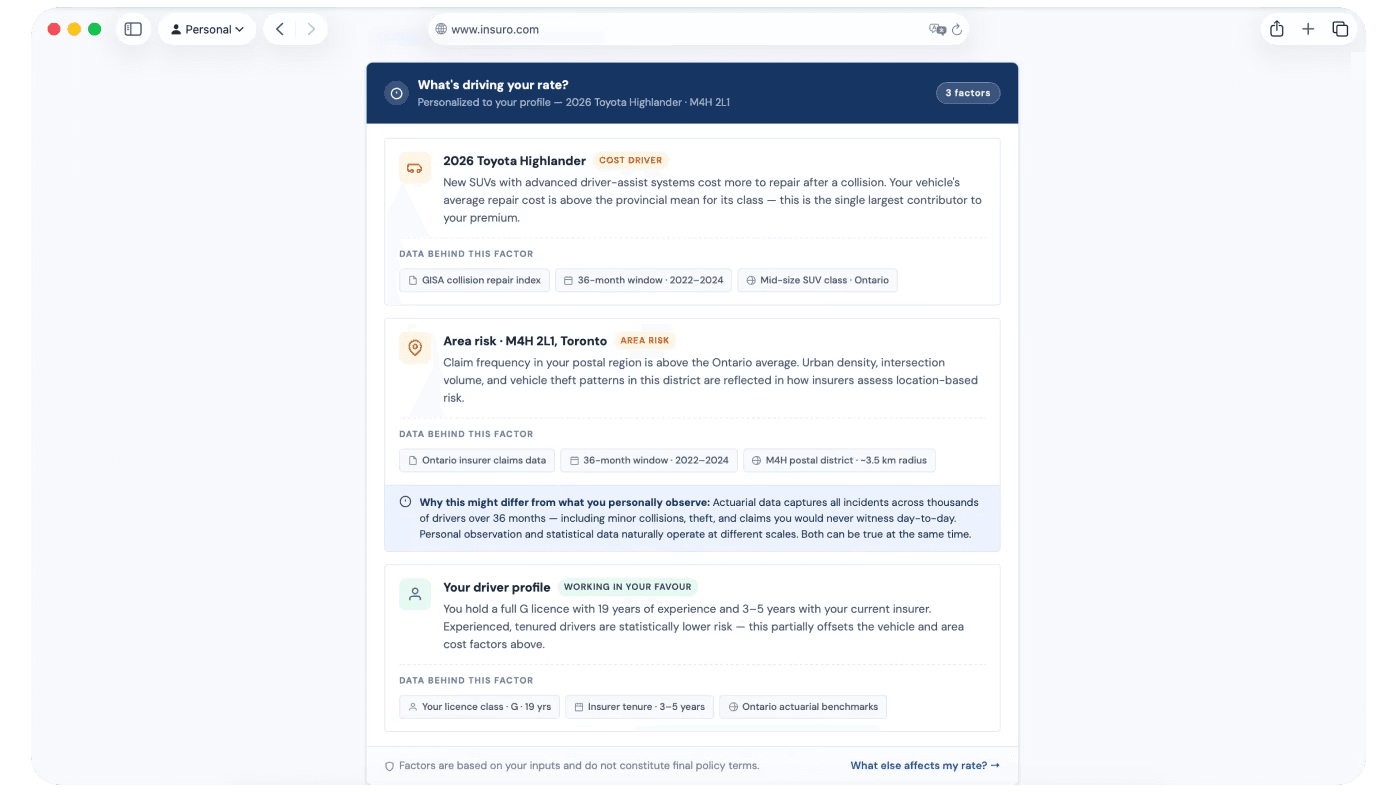
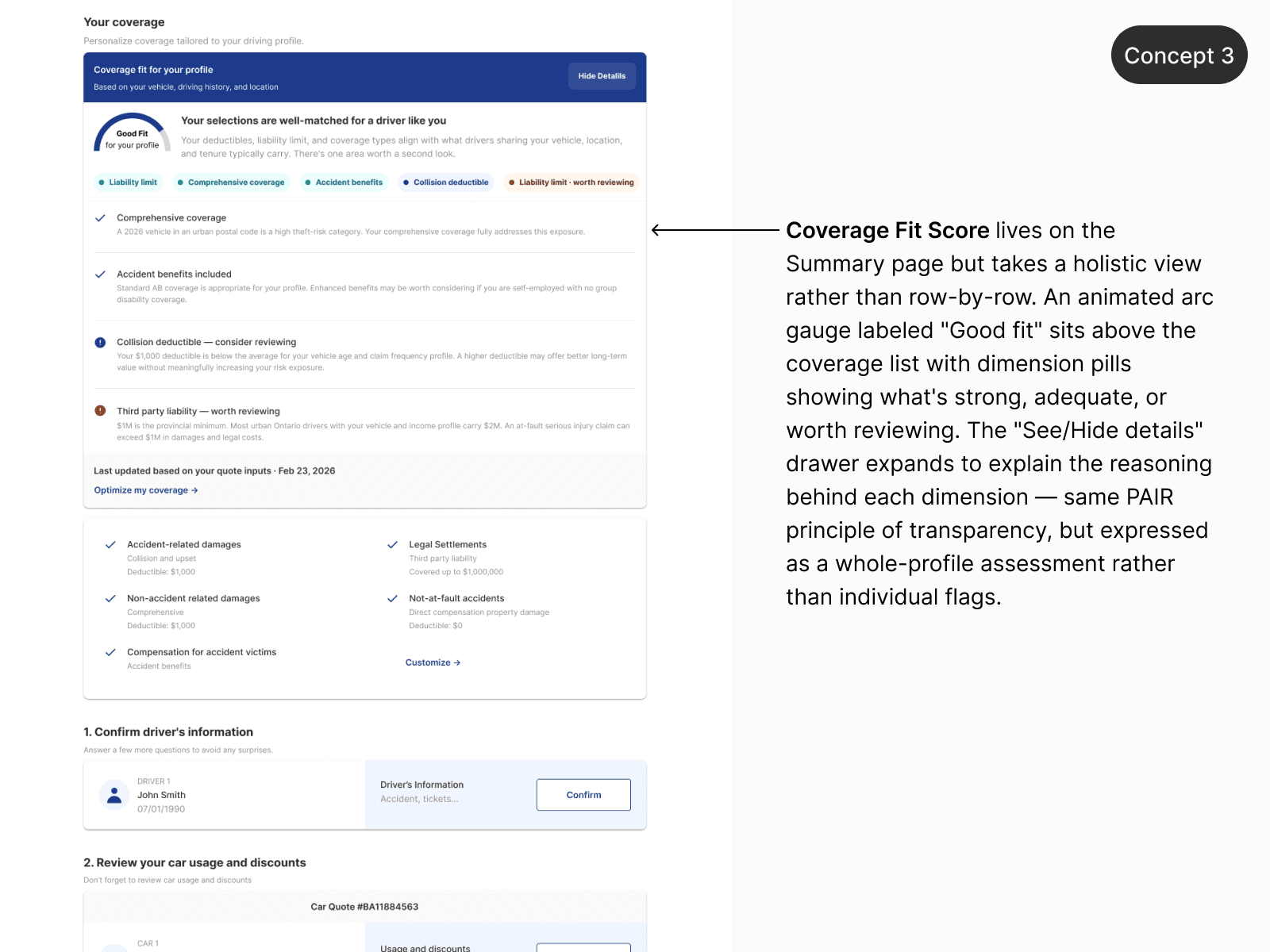
Rather than redesigning the quoter or building an AI agent, the approach was to find the single point where trust most plausibly broke down — and treat it as a placement and language challenge. Using Google's PAIR Guidebook as a foundation, the guiding principle became helping users form an accurate mental model of what they're buying and why it costs what it costs.
Four concepts were explored. One cleared every constraint bar as the strongest hypothesis: a rate transparency module — a dynamic callout triggered by profile inputs, surfacing two or three plain-language explanations of what's likely driving the user's premium. The content already existed inside actuarial teams. No ML pipeline, no chat UI, no new infrastructure required.
The underlying bet was that price dominates insurance decisions not because users are purely price-driven, but because price is the only thing they can easily compare. Making the abstract concrete gives users something to evaluate beyond the number — and that shifts the decision frame.


Testing & Iteration
When data contradicts lived experiences
Light user testing pointed toward the rate transparency module as the most well-received concept — but surfaced a credibility gap that hadn't been anticipated. Explanations referencing area risk factors were being challenged by users whose personal experience didn't match.
"I haven't seen a single accident in this area in the last year. Why does your data say otherwise?"
USER TESTING FEEDBACK
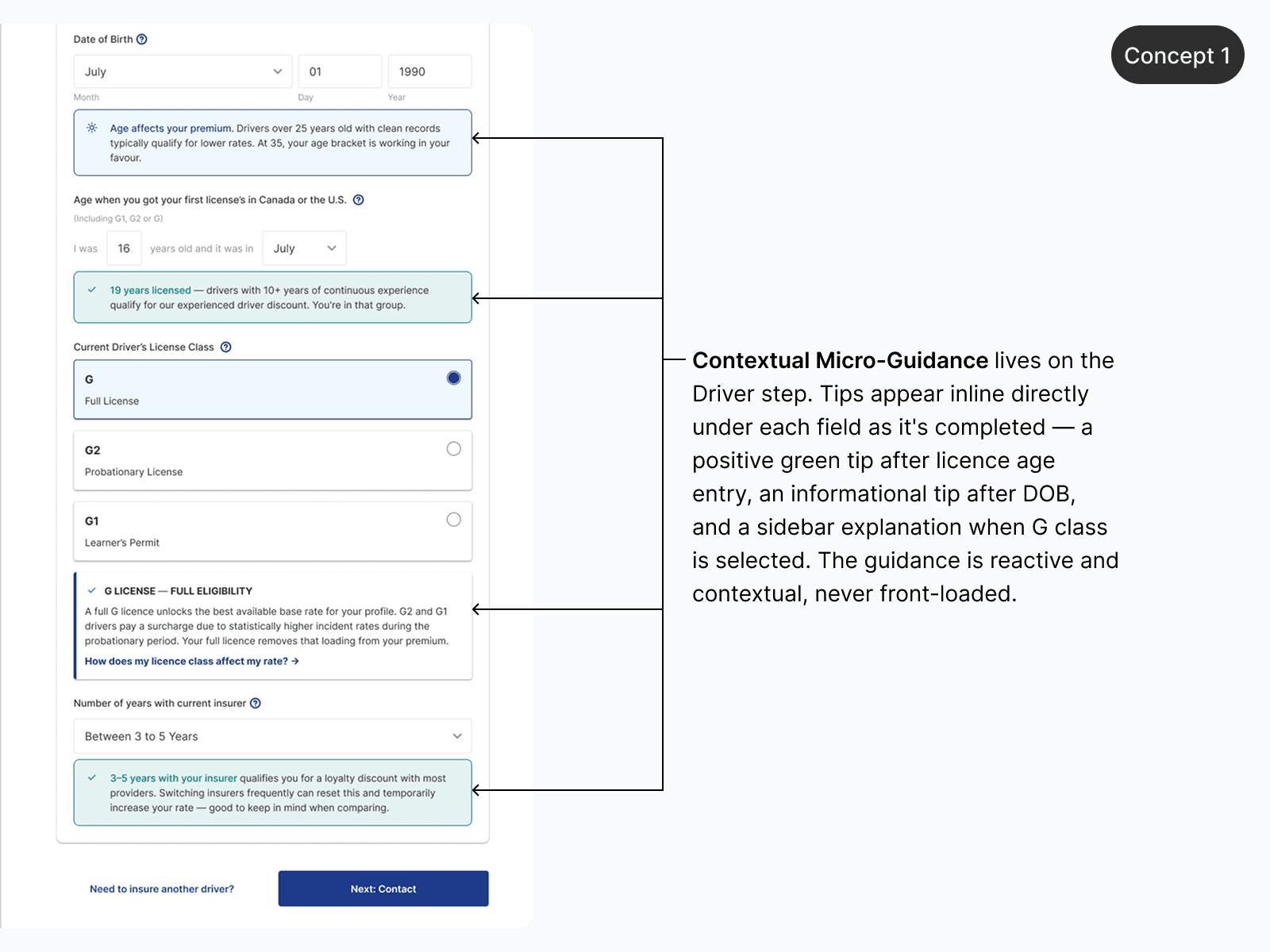
PAIR addresses this directly through calibrated confidence: a system that asserts statistical facts as ground truth will lose to a user's lived experience every time. Two A/B iterations were designed to test different answers.
Iteration A builds credibility through transparency. Iteration B builds trust through acknowledgment. Beyond conversion, measuring task drop-off depth for B could reveal where in the funnel trust actually forms — signal that matters regardless of which variant wins.
Iteration A — Credibility via Transparency · Each explanation surfaces its data source, time window, and geographic radius — showing that personal observation and actuarial data operate at different scales. The goal is a mental model update, not a contradiction. Tradeoff: Risk of cognitive overload if context isn't distilled precisely. A footnote becomes a liability if it reads like fine print.
Iteration B — Trust via Acknowledgment · Explanations use honest uncertainty framing ("Our data suggests…") paired with an inline prompt: "Does this reflect your experience?" A "no" opens a brief explanation of why actuarial and personal data diverge — validating skepticism rather than dismissing it. Tradeoff: Adds an interaction step that could introduce friction. Success depends on whether acknowledgment outweighs the added cognitive cost.
Reflection
What working without a net taught me
No research, no baseline, and no data access forced a different kind of rigor: building an argument from first principles, staying honest about what was known versus assumed, and designing for iteration rather than completion.
The PAIR framework was useful because it insists on honesty — about what the AI does, what it doesn't know, and where human judgment should remain in control. In a domain where users arrive skeptical and have been burned before, that honesty isn't just an ethical consideration. It's the product strategy.
The minimum viable version ships as three to five contextual callout modules embedded in the existing quoter. Before quote-to-purchase data accumulates, the first thing to instrument is module engagement itself — whether users read it, expand it, or interact with it at all. That's a meaningful leading indicator that doesn't require waiting for conversion cycles to close.
Next Steps
How this moves forward
I would define a proxy metric that can signal value before purchase data accumulates.
Module engagement — whether users read, expand, or interact with the transparency callout — would be instrumented from day one. A high read-through rate with low abandonment on that step would suggest early signal that the content is building the right context, not creating friction.
I believe Iteration B should only move forward if Iteration A shows strong enough module engagement to justify the added interaction cost since stacking micro-interactions on top of content that users aren't reading would compound the problem rather than solve it.
The learning question for the first period: "does surfacing rate context during the quote flow reduce the "why are my rates going up" pattern in post-sale conversations?"
If there is measurable drop in that sales objection, it would validate the core hypothesis faster than any conversion metric. It's a tighter feedback loop that doesn't require waiting for a full purchase or renewal cycle, and it would indicate whether the product is solving the right problem before committing to a broader rollout.